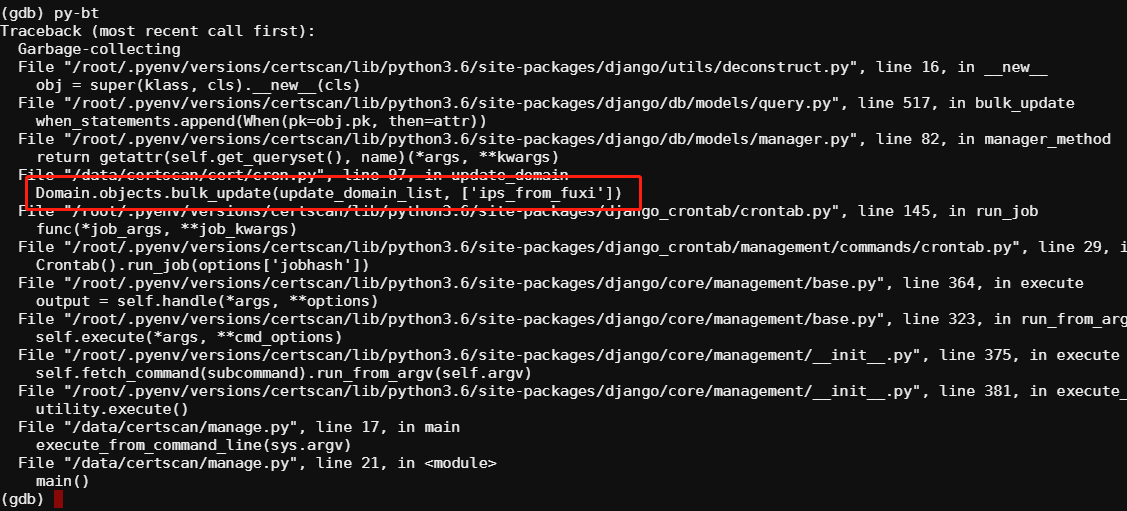
本文链接: https://mp.weixin.qq.com/s/AvLpKKsqRkzdzatvqqvfuQ
背景
随着时间推移,BBScan作为一款漏洞扫描工具已经过时,在9年前,这样的工具还能够以数量和速度优势,捡到一些中低危漏洞,但如今,确实是扫不到什么有价值的东西了。
常见Web框架引入了更多的默认安全设计、WAF/RASP等防护技术更加成熟,曾经常见的SQL注入/XSS/命令注入等,现在反而见得不多了。取而代之的,各大SRC现在收到的漏洞中,有相当比例是逻辑越权类的。
于是,笔者对这款古董级的BBScan进行了如下改造
- 支持Web指纹识别,帮助安全工程师快速定位到感兴趣的应用
- Web指纹来自 https://github.com/0x727/FingerprintHub 感谢作者
- 支持Javascript 解析功能
- 目前很多站点是单页应用,对扫描器可见的仅仅是静态资源打包后的少数几个.js。扫描器需要解析js,扫描诸如 Token/Secrets/Password/Key 泄露,发现API接口
- 支持从javascript文件中,正则提取疑似API接口
- 在当前版本中,考虑到速度,并没有对提取的URL进行自动化测试,但计划增加一个heavy mode ,扫描API接口
- 减少漏报: 优化减少DNS查询次数,提高稳定性。在家庭网络环境下,观察到DNS设施相对脆弱,容易出现漏报问题
- 减少误报:优化了误报验证逻辑
- 界面优化:对输出的HTML报告,进行了简单优化,提升可读性
改造效果
BBScan项目地址:https://github.com/lijiejie/BBScan
笔者首先利用另一个工具 subDomainsBrute暴力枚举了3个域名
*.baidu.com *.qq.com *.bytedance.com随后将发现的域名文件丢给BBScan,扫描生成3份报告(请复制后打开)
- https://www.lijiejie.com/python/BBScan/qq.com_report.html
- https://www.lijiejie.com/python/BBScan/bytedance.com_report.html
- https://www.lijiejie.com/python/BBScan/baidu.com_report.html

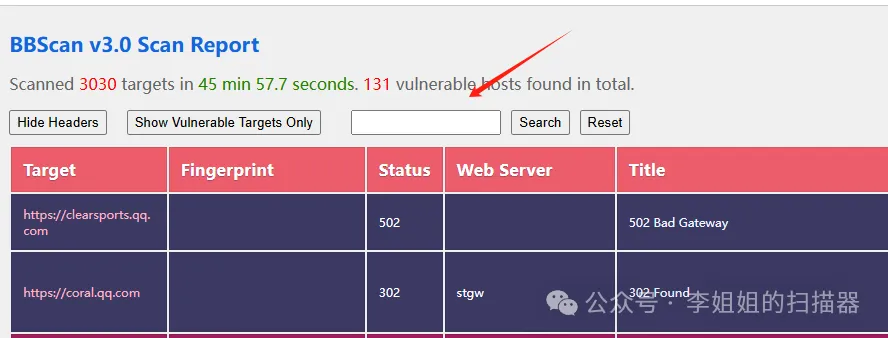
如上图所示,扫描器利用默认的内置规则,能够识别到这是一个管理后台。同时,扫描器还从js文件中,提取到12个疑似API接口。
针对这样的一份报告,可以进行如下处理
- 首先检查通过内置规则扫出的漏洞,一般是信息泄露、各类后台、JS中的秘钥泄露
- 检查web指纹是否识别到你可能感兴趣的通用应用、框架、开源或商业产品
- 对发现API接口的站点,进行重点分析和测试,点开感兴趣的接口重点分析和扫描
- 对API网关进行测试和评估
- 对报告中泄露的内网域名、IP进行简单分析
- 通过关键词搜索你感兴趣的关键词,如Header Name、特殊的Cookie
使用问题
对大量目标快速指纹识别
- python BBScan.py –fingerprint -f urls.txt –api
请注意, 这个 –fingerprint 开关,是指定只扫描web指纹,其他规则反而会被禁用。
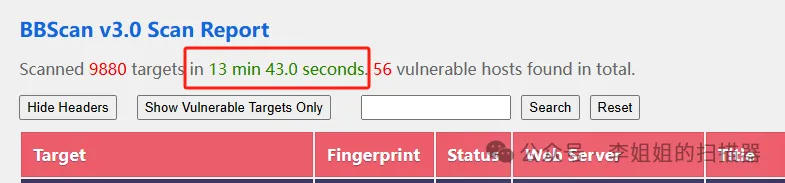
如下图所示,本工具可以在较短时间内扫描完上万网站
完整扫描模式
- python BBScan.py -f baidu.com_full.txt –full –api
–network MASK 任何时候都可以使用该参数,把子网中的其他相邻IP,一并添加到扫描任务中。虽然不建议这么做,但下面的命令是真的可以工作,你或许会得到1个超大HTML
- –host 10.1.1.1 –network 8 –fingerprint
上面的命令指定扫描 10.1.1.1/8 整个内网,打开文件时,可能出现Chrome浏览器Out Of Memeory,所以,建议指定为更小的指,建议不小于16。
–skip, –skip-intranet 排除内网IP的扫描,这对白帽子比较实用,避免浪费扫描资源。
未来优化
BBScan未来可能进一步优化API接口的扫描
- 增加对API接口的重扫描、分析支持
- 正则优化,解决API接口提取不够精准的问题
- 优化对隐蔽API接口的暴力枚举发现、source map泄露发现等
- 子域名/Email的收集整理、证书的收集整理
因时间有限,部分功能还未开发完成,同时,开发过程测试不充分,请大家反馈功能建议和Bug问题。 🙂
古董扫描器BBScan的复活,希望它对你有一定用。虽然,显然还不够有用。 🙂