前文介绍了生成DNS查询,本文继续介绍如何解码DNS服务器发回的响应文本。
首先应该明确,响应和查询的基本格式是一样的,都是由5个部分组成:header、Question、Answer、 Authority、Additional。并且,Header的格式也完全相同。
检查RCODE的值
拿到Response首先应该检查RCODE,因为域传送多半并不成功。检查第3个字节的最后四位即可:
RCODE = struct.unpack('!H', response[2:4] )[0] & 0b00001111 # last 4 bits is RCODE
if RCODE != 0:
print 'Transfer Failed. %>_<%'
sys.exit(-1)
这里是拿两个字节和二进制数00001111取and。
读Answer RRs的值
RRs是指Resource Record,资源记录。 该值位于第7、8字节。
跳过Header和Query
在前文查询消息中,已经记录了Query区块的长度,用到这里直接跳到Answers区块:
OFFSET = 12 + LEN_QUERY + 4 # header = 12, type + class = 4
12是Header的长度。
读取所有记录
Answer记录的基本格式是:
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| |
/ /
/ NAME /
| |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| TYPE |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| CLASS |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| TTL |
| |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
| RDLENGTH |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--|
/ RDATA /
/ /
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
这里很关键的是Name字段。它有两种格式:
- 跟前一篇提到的Query格式相同,直接用Label序列表示。
- 用一个偏移量,来指示前文中已经出现的某个位置。实际上,这是为了压缩文本,前面已经出现过的文本,不再重复。
如果是第二种表示法,则起始的两个字节是:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 1 | 1 | 消息内部的偏移量 | |||||||||||||
于是,只需要检查前两个字节,就可以知道Name采用了何种表示法了。如果为11,就跳到对应的偏移位置去读域名。
当Type的值为1,即A记录时,RDLENGTH的值是4,并且RDATA表示的是4个字节的IP地址。循环读取记录直到消息结尾。
笔者只处理了A记录:
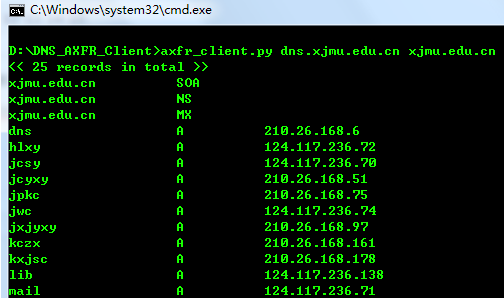
建议在编码的时候,一定要使用WireShark抓包,并且对照分析各个section的内容。